Unlimited-OCR 是百度近期发布并开源的端到端 OCR 模型,面向长文档、复杂版式和多页文档解析场景,具备长文档解析和信息提取能力,可应用于知识库构建、智能问答、企业文档处理、档案数字化、合同与报告解析等场景。随着企业知识库、智能办公、合同审核、科研资料处理等场景对高质量文档理解能力的需求提升,长文档解析正成为大模型应用落地的重要基础能力。
7月3日消息,百度智能云宣布开放文档解析(Unlimited-OCR)企业级 API 服务,并同步开启公测。用户通过百度智能云平台无需自行部署模型,即可快速体验长文档解析效果,完成模型验证、业务测试和场景探索。公测期间,个人实名用户可获取 200 页免费额度,企业实名用户可获取 1000 页免费额度。
Unlimited-OCR 是百度近期发布并开源的端到端 OCR 模型,面向长文档、复杂版式和多页文档解析场景,具备长文档解析和信息提取能力,可应用于知识库构建、智能问答、企业文档处理、档案数字化、合同与报告解析等场景。
作为百度开源的文档解析模型,Unlimited-OCR 发布后迅速获得全球开发者关注。据官方信息,模型发布次日即登顶 GitHub Daily Trending 榜和 Python 榜,GitHub Star 仅 5 天突破 1 万;同时在 Hugging Face 全球模型总趋势榜和多模态模型趋势榜均排名第一,实现 GitHub、Hugging Face 四榜第一,展现出较高的社区关注度和开源影响力。
在模型能力方面,Unlimited-OCR 面向长文档解析场景打造,总参数规模 3B,推理时激活参数约 570M。公开评测结果显示,Unlimited-OCR 在 OmniDocBench v1.6 基准测试中取得 93.92% 综合成绩,刷新端到端 OCR 相关纪录;在保持高精度解析能力的同时,真实文档场景推理速度较 DeepSeek OCR 提升约 12.7%,当输出长度达到 6000 tokens 时,速度优势扩大至约 35%。
长文档解析一直是 OCR 技术落地中的重要难点。过去面对书籍、论文、报告等长文档,行业通常采用“逐页解析+结果拼接”的方式,随着输出内容增长,模型解码阶段的 KV Cache 持续膨胀,推理速度和显存成本也随之上升。针对这一问题,百度在 Unlimited-OCR 中提出 Reference Sliding Window Attention(R-SWA)机制,使模型在保持对原始文档内容关注的同时,仅保留最近一段生成内容作为“工作记忆”,从而在一次前向推理中连续完成多页文档解析,并将解码阶段的 KV Cache 控制在相对恒定规模。
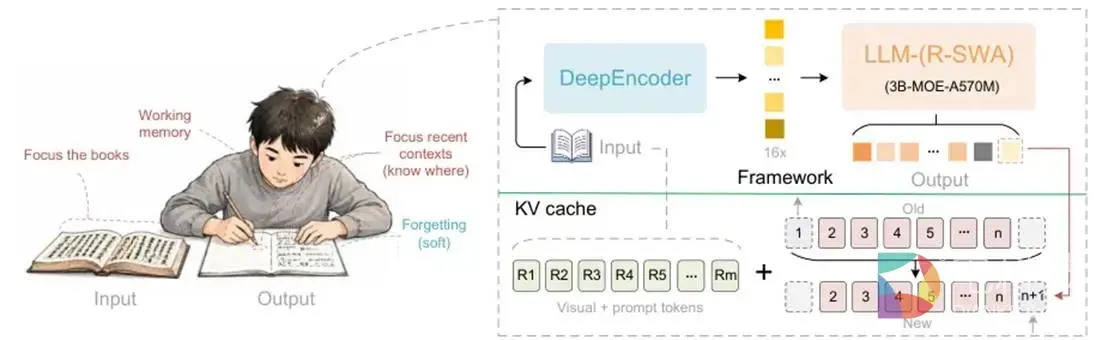
随着企业知识库、智能办公、合同审核、科研资料处理等场景对高质量文档理解能力的需求提升,长文档解析正成为大模型应用落地的重要基础能力。通过百度智能云公有云平台,开发者和企业无需自行准备推理环境和算力资源,即可直接测试 Unlimited-OCR 在真实文档场景中的解析效果,并将更多精力投入业务场景测试和应用集成。
评论区(0)